網頁爬蟲 APIs
從全球數百個公共網站即時擷取資料。透過 API 快速存取結構化資料,以節省開發和維護成本。

無需開發或自建伺服器。
全面覆蓋熱門平台(如 Amazon、YouTube)
結構化資料輸出(JSON / HTML 格式)
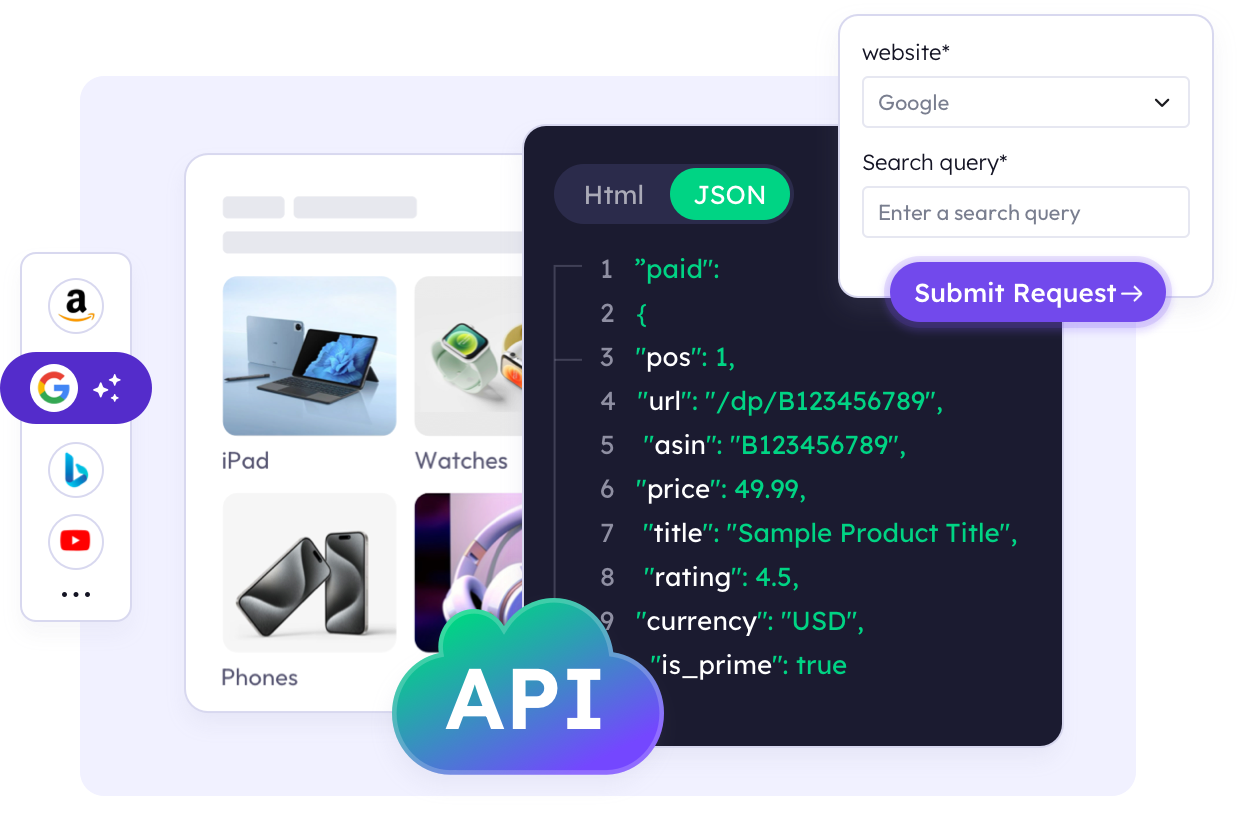
瀏覽我們豐富的範本庫,滿足您所有爬蟲需求。
沒有數據
存取困難網站的資料從未如此簡單。透過實用的程式碼範例,探索 Web Scraper API 的強大功能。
curl -X POST https://scraper.smartproxy.org/v1/query -H "Authorization: Basic XXX" -H "Content-Type: application/json" -d "{"source":"amazon_search","context":{"keyword_list":[{"keyword":"MacBook"}],"start_page":1,"pages":2},"geo":"US"}"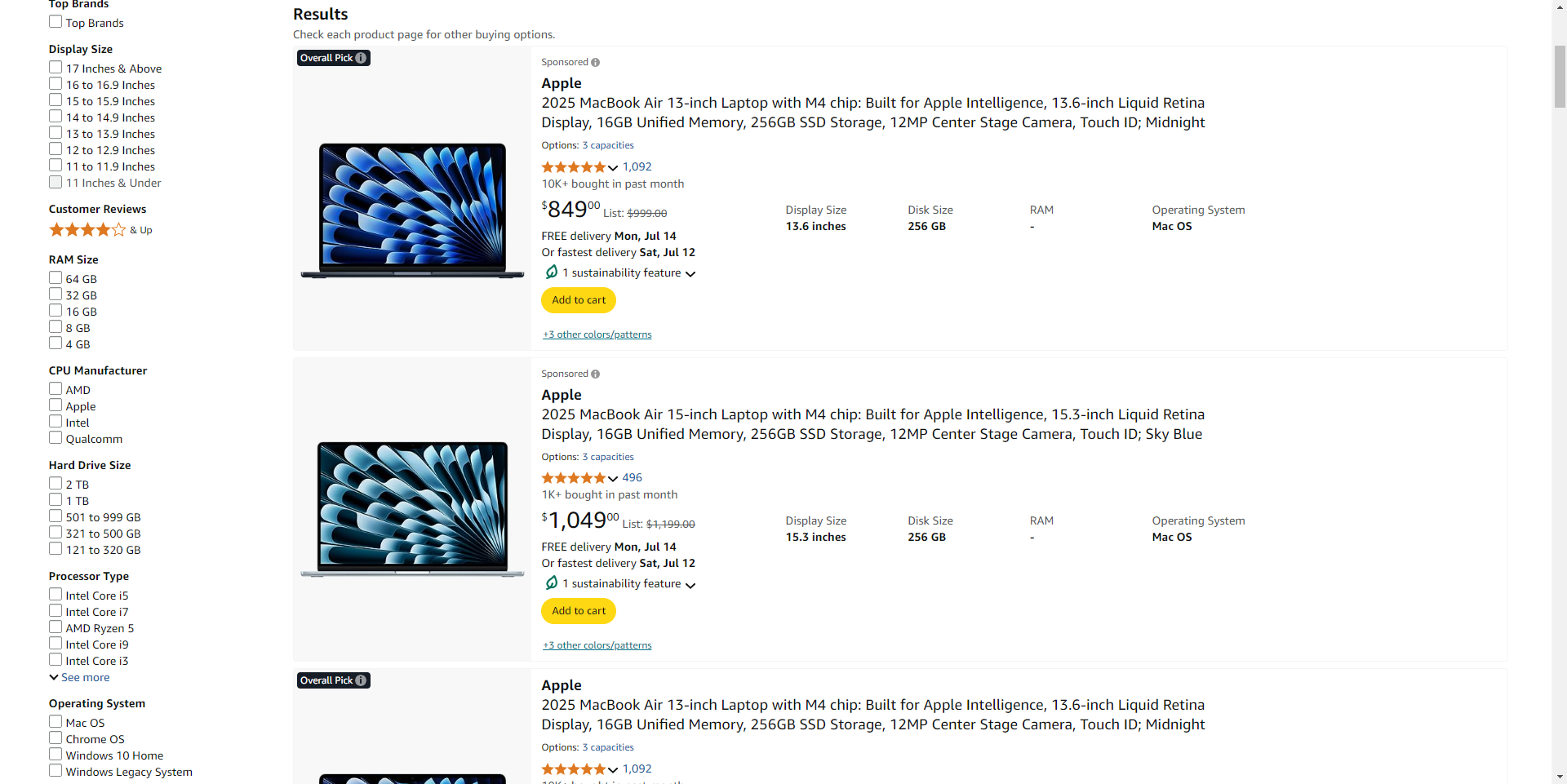
企業級數據解決方案,助力智慧成長。免費試用 Web Scraper API,根據您的業務需求量身打造。
獲取 $-/1K 結果 價格方案
注意:不支援存取受政策限制的網站,例如與金融或政府相關的網站。
我們接受以下支付方式:
熱門地區:美國、英國、加拿大、印度、巴西、墨西哥
住宅代理輪換
HTTP/SOCKS5
按國家和城市級別定位
平均成功率99.5%
專屬客戶服務經理
支持API和用戶密碼認證
IP可用性99.9%
依賴全球領先的代理基礎設施,確保穩定效能並將失敗率降至最低。
利用生產級 API,讓您的爬蟲自動化,節省資源並降低維護成本。
輕鬆擴展您的爬蟲專案,滿足數據需求並保持最佳效能。
偵測數據結構與模式,確保高效且精準的資料擷取。
減輕伺服器負載,優化大量爬蟲任務的數據收集。
高效將原始 HTML 轉換為結構化資料,簡化整合與分析。
確保數據可靠性,節省人工檢查與前處理時間。
全面、可擴展且合規的網頁數據擷取
從任何網站獲取結構化資料——只需告訴我們網域與所需資料點。我們將為您量身打造精準的爬蟲 API 解決方案。可選擇 JSON、NDJSON、CSV 等格式,並透過 Webhook 或 API 無縫整合到您的工作流程。

無需代理、無封鎖——內建解鎖與自動化,輕鬆從任何地點收集數據。全自動、可靠又省時——您的數據,無縫交付。
嚴格遵守數據保護法規(GDPR、CCPA),確保用戶數據安全與隱私。

SmartProxy面向企業和個人,提供穩定、安全且高度可客製化的智慧代理和智慧代理服務。
Proxy Knowledge Guide
If you can't find something or need assistance, please contact us at [email protected]




